




What is ORM?
ORM stands for Objects to Relational Mapping, means providing the mapping between class with table and member variable with columns is called ORM. ORM is the automated persistence of objects in a java application to the tables in a relational database. ORM is a programming method to map the objects in java with the relational entities in the database. In this, entities/classes refers to table in database, instance of classes refers to rows and attributes of instances of classes refers to column of table in database. This provides solutions to the problems arise while developing persistence applications using traditional JDBC method. This also reduces the code that needs to be written.
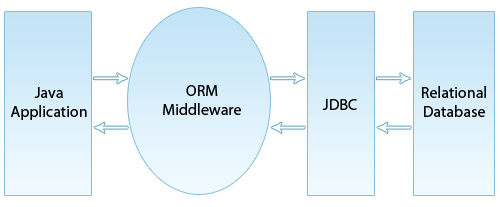
What are the different ORM frameworks available on Java?
ORM tools are:
- Hibernate
- Open JPA
- Enterprise JavaBeans Beans(EJB3)
- Java Data Objects (JDO)
- Oracle TopLinks
- Spring DAO
- MyBatis
What does an ORM solution consists of?
An ORM solution consists of the following four pieces:
- API for performing basic CRUD(Create, Read, Update, Delete) operations.
- API to express queries referring to classes.
- Facilities to specify mapping metadata.
- Optimization facilities : dirty checking, lazy associations fetching.
What are the different levels of ORM quality?
There are four levels defined for ORM quality as follows.
a). Pure relational (Stored Procedure).
b). Light object mapping (JDBC).
c). Medium object mapping.
d). Full object mapping (Composition, Inheritance, Polymorphism etc )
What is a Pure relational ORM?
The whole application, including the user interface, is designed around the relational model and SQL-based relational operations. This approach, despite its deficiencies for large systems, can be an excellent solution for simple applications where a low level of code reuse is tolerable. Direct SQL can be fine-tuned in every aspect, but the drawbacks, such as lack of portability and maintainability, are significant, especially in the long run. Applications in this category often make heavy use of stored procedures, shifting some of the work out of the business layer and into the database.
What is a meant by Light object mapping?
The entities are represented as classes that are mapped manually to the relational tables. The code (SQL / JDBC) is hidden from the business logic using well known design patterns. This approach is extremely widespread and is successful for applications with a small number of entities, or applications with generic, metadata-driven data models.
The entities are represented as classes that are mapped manually to the relational tables. The code (SQL / JDBC) is hidden from the business logic using well known design patterns. This approach is extremely widespread and is successful for applications with a small number of entities, or applications with generic, metadata-driven data models.
What is a meant by Medium object mapping?
The application is designed around an object model. The SQL code is generated at build time using a code generation tool, or at runtime by framework code. Associations between objects are supported by the persistence mechanism, and queries may be specified using an object-oriented expression language. Objects are cached by the persistence layer. A great many ORM products and homegrown persistence layers support at least this level of functionality. It’s well suited to medium-sized applications with some complex transactions, particularly when portability between Object/relational mapping different database products is important. These applications usually don’t use stored procedures.
What is meant by Full object mapping?
Full object mapping supports sophisticated object modeling: composition, inheritance, polymorphism, and “persistence by reach ability”. The persistence layer implements transparent persistence; persistent classes do not inherit any special base class or have to implement a special interface. Efficient fetching strategies (lazy and eager fetching) and caching strategies are implemented transparently to the application. This level of functionality can hardly be achieved by a homegrown persistence layer it’s equivalent to months or years of development time. A number of commercial and open source Java ORM tools have achieved this level of quality.
What are the advantages of using ORM tools like Hibernate?
What are the advantages of using ORM tools like Hibernate?
Performance:
1. Hibernate employs very aggressive, and very intelligent first and second level caching strategy. This is a major factor in achieving the high scalability.
2. Hibernate spares you unnecessary database calls and in persistence state it is automated persistence then it still increases the performance.
Portability: Hibernate portability across the relational databases is amazing. It is literally one configuration parameter change. We need to change the database dialect.
Productivity:Hibernate reduces the burden of developer by providing much of the functionality and let the developer to concentrate on business logic.
Maintainability: As hibernate provides most of the functionality, the LOC (Lines of Code) for the application will be reduced and it is easy to maintain. By automated object/relational persistence it even reduces the LOC.
Cost Effective: Hibernate is free and open source – Cost Effective
Learning curve is short: Since we all have working experience in using Hibernate, and Hibernate is totally object orientated concept, it will shorted our learning curve.
- Hibernate is an open-source and lightweight ORM tool that is used to store, manipulate and retrieve data from the database.
- Hibernate is a pure Java object-relational mapping (ORM) and persistence framework that allows us to map plain old Java objects to relational database tables using (XML) configuration files. It supports the object oriented principles such as association, inheritance, polymorphism, composition and collections.
- Note: The story behind the name of Hibernate is “An object is sent to hibernation to a RDBMS, when it comes back (if it does) it wakes up from his hibernation".
- Hibernate is primarily used in Data Access Layer to persist our application data into the Database.
- Its purpose is to relieve the developer from a significant amount of relational data persistence-related programming tasks. Hibernate implements JPA (Java persistence API) that makes it worldwide acceptable.
- Note: JPA implementation means that it follows the rules that have been specified in Java Persistence API’s specifications so that later if you don’t want to use Hibernate you can use some other provider that implements Java Persistence API and that can be done with a minimal code changes.
Java Persistence API (JPA) provides specification for managing the relational data in applications. Current JPA version 2.1 was started in July 2011 as JSR 338. JPA 2.1 was approved as final on 22 May 2013.
JPA specifications is defined with annotations in javax.persistence package. Using JPA annotation helps us in writing implementation independent code.
What is Persistence?
Persistence is a process of storing data to a permanent storage medium like SQL database. Hibernate provides transparent persistence for Plain Old Java Objects (POJOs). Persistent class is a no-argument constructor, not public.
What is Persistence Framework?
Persistence frame work: Persistence frame work moves the data in its natural form to and from the permanent storage of data i.e. database.
What is Mapping?
Mapping is a technique, used to copy the tables to object and objects to table. Using object relational mapping you can reuse your code. Mapping Java classes to database tables is accomplished through the configuration of an XML file or by using Java Annotations.
What are POJOs?
POJO stands for plain old java objects. These are just basic JavaBeans that have defined setter and getter methods for all the properties that are there in that bean. Besides they can also have some business logic related to that property. Hibernate applications works efficiently with POJOs rather then simple java classes.
POJO stands for plain old java objects. These are just basic JavaBeans that have defined setter and getter methods for all the properties that are there in that bean. Besides they can also have some business logic related to that property. Hibernate applications works efficiently with POJOs rather then simple java classes.
In Hibernate, after creating the bean object, we should set values to bean and save or update bean object to session or after setting we can get values from bean if we want to fetch bean data.
What is object/relational mapping metadata?
ORM tools require a metadata format for the application to specify the mapping between classes and tables, properties and columns, associations and foreign keys, Java types and SQL types. This information is called the object/relational mapping metadata. It defines the transformation between the different data type systems and relationship representations.
What is Attribute Oriented Programming?
XDoclet has brought the concept of attribute-oriented programming to Java. Until JDK 1.5, the Java language had no support for annotations; now XDoclet uses the Javadoc tag format (@attribute) to specify class-, field-, or method-level metadata attributes. These attributes are used to generate hibernate mapping file automatically when the application is built. This kind of programming that works on attributes is called as Attribute Oriented Programming.
What are the important benefits of using Hibernate Framework?
Some of the important benefits of using hibernate framework are:
- Hibernate eliminates all the boiler-plate code that comes with JDBC and takes care of managing resources, so we can focus on business logic.
- Hibernate framework provides support for XML as well as JPA annotations, that makes our code implementation independent.
- Hibernate provides a powerful query language (HQL) that is similar to SQL. However, HQL is fully object-oriented and understands concepts like inheritance, polymorphism and association.
- Hibernate is an open source project from Red Hat Community and used worldwide. This makes it a better choice than others because learning curve is small and there are tons of online documentations and help is easily available in forums.
- Hibernate is easy to integrate with other Java EE frameworks, it’s so popular that Spring Framework provides built-in support for integrating hibernate with Spring applications.
- Hibernate supports lazy initialization using proxy objects and perform actual database queries only when it’s required.
- Hibernate cache helps us in getting better performance.
- For database vendor specific feature, hibernate is suitable because we can also execute native sql queries.
The following are the advantages of Hibernate over JDBC:
- Hibernate is data base independent, same code will work for all databases like ORACLE, MySQL, and SQLServer etc. In case of JDBC query must be data base specific.
- As Hibernate is set of Objects, no need to learn SQL language. We can treat TABLE as an Object. Only Java knowledge is need. In case of JDBC we need to learn SQL.
- Don’t need Query tuning in case of Hibernate. If we use Criteria Quires in Hibernate then hibernate automatically tuned our query and return best result with performance. In case of JDBC we need to tune our queries.
- Hibernate supports Cache mechanism by this, the number of round trips between an application and a database will be reduced. By using this technique, an application performance will be increased automatically. Hibernate support two levels of cache mechanism those are first level and second level. In case JDBC, there is no cache mechanism. There is no temporary memory to store any kind of data.
- In hibernate, if database schema (table) doesn’t exist, then hibernate will automatically create schema for us. In case of JDBC, if already table exists then only we can insert the data otherwise JDBC throws Exception.
- Development fast in case of Hibernate because we don’t need to write queries.
- No need to create any connection pool in case of Hibernate. We can use c3p0. In case of JDBC we need to write our own connection pool.
- Hibernate is supporting Annotation Mappings. By using this mapping we can get ultimate performance. In case of JDBC there are no Annotations.
- There are two types of loading the data from the database i.e Lazy loading and Eager loading. Hibernate support the both types. In case of JDBC it supports only Eager loading.
- Hibernate Supports automatic versioning of rows but JDBC Not. Automatic versioning is a simple technique for assuring data integrity.
- Hibernate is supporting auto incremented value or uniquely generated random numbers. There are several types auto generators. We can use any type of generators. JDBC is not providing any auto increment values to the unique column of the table. Developer has to take care of providing auto increment. In case of Oracle, sequence. In case of MySQL, auto increment.
- In hibernate an exception translator is given. So it converts the checked exceptions into unchecked exception (HibernateException). So in hibernate we have only unchecked exceptions. If all exceptions are unchecked we are no need to use try and catch blocks or throws Exception. In JDBC all exceptions are checked exceptions, so we must write to code in try catch or throws.
- Hibernate supports Inheritance, Association (relationships) and Collections. In hibernate, if we save the derived class object then automatically its base class object will also be stored into database, it means Hibernate supports the inheritance. Hibernate supports relationships like One to One, One to Many, Many to One and Many to Many Hibernate supports collections like List, Set and Map etc. These features are not present with JDBC API.
- Hibernate implicitly provides the transaction management, in fact most of the queries can't be executed outside the transaction. In case of JDBC API, we need to write code for transaction management using commit and rollback.
The following are the disadvantages of Hibernate
- Performance decreases in complex data: For complex data, mapping from Object-to-tables and vice versa reduces performance and increases time of conversion.
- Not allow all queries: Hibernate does not allow some type of queries which are supported by JDBC. For example it does not allow inserting multiple objects to same table using single query. Developer has to write separate query to insert each object.
- Debugging: Sometimes debugging and performance tuning becomes difficult.
- Slower than JDBC: Hibernate is slower than pure JDBC as it is generating lots of SQL statements in runtime.
- Not suitable for Batch processing: It advisable to use pure JDBC for batch processing.
- Composite mapping is complex: If you do not understand it, yes it is complex. But this will not be a disadvantage. We have talked about this here mapping composite keys in hibernate.
- High memory consumption: Loading a large number of objects from the database which then reside in memory cause to waste the memory. One approach to resolving this is by using lazy loading, which has a few of its own caveats.
- Difficulties in legacy databases: Hibernate works best and easiest with a brand new database, attempting to use it on an existing legacy database can be quite a difficult task.
Why hibernate is advantageous over Entity Beans & JDBC?
An entity bean always works under the EJB container, which allows reusing of the object external to the container. An object can not be detached in entity beans and in hibernate detached objects are supported.
Hibernate is not database dependent whereas JDBC is database dependent. Query tuning is not needed for hibernate as JDBC is needed. Data can be placed in multiple cache which is supported by hibernate, whereas in JDBC the cache is to be implemented.
What are the main differences between EJB 3.0 & Hibernate?
Hibernate
|
EJB 3.0
|
Session–Cache or collection of loaded objects relating to a single unit of work
|
Persistence Context-Set of entities that can be managed by a given EntityManager is defined by a persistence unit.
|
XDoclet Annotations used to support Attribute Oriented Programming
|
Java 5.0 Annotations used to support Attribute Oriented Programming.
|
Defines HQL for expressing queries to the database
|
Defines EJB QL for expressing queries.
|
Supports Entity Relationships through mapping files and annotations in JavaDoc
|
Support Entity Relationships through Java 5.0 annotations.
|
Provides a Persistence Manager API exposed via the Session, Query, Criteria, and Transaction API
|
Provides and Entity Manager Interface for managing CRUD operations for an Entity.
|
Provides callback support through lifecycle, interceptor, and validatable interfaces
|
Provides callback support through Entity Listener and Callback methods.
|
Entity Relationships are unidirectional. Bidirectional relationships are implemented by two unidirectional relationships
|
Entity Relationships are bidirectional or unidirectional.
|
Can you tell few databases hibernate will support?
Hibernate supports following RDBMS:
- MySQL
- Oracle
- PostgreSQL
- FrontBase
- DB2/NT
- Microsoft SQL Server Database
- Sybase SQL Server
- Informix Dynamic Server
- HSQL Database Engine and many more...
How will you configure Hibernate?
The configuration files hibernate.cfg.xml (or hibernate.properties) and mapping files *.hbm.xml are used by the Configuration class to create (i.e. configure and bootstrap hibernate) the SessionFactory, which in turn creates the Session instances. Session instances are the primary interface for the persistence service.
”hibernate.cfg.xml” (alternatively can use hibernate.properties): These two files are used to configure the hibernate service (connection driver class, connection URL, connection username, connection password, dialect etc). If both files are present in the classpath then hibernate.cfg.xml file overrides the settings found in the hibernate.properties file.
”Mapping files” (*.hbm.xml): These files are used to map persistent objects to a relational database. It is the best practice to store each object in an individual mapping file (i.e mapping file per class) because storing large number of persistent classes into one mapping file can be difficult to manage and maintain. The naming convention is to use the same name as the persistent (POJO) class name. For example Account.class will have a mapping file named Account.hbm.xml. Alternatively hibernate annotations can be used as part of your persistent class code instead of the *.hbm.xml files.
Explain how to configure Hibernate?
Hibernate uses a file by name hibernate.cfg.xml. This file creates the connection pool and establishes the required environment. A file named .hbm.xml is used to author mappings. The bootstrap action is configured by using Configuration interface.
There are two types of environment to configure hibernate:
1. Managed Environment: The definitions of database operations such as connections, transaction boundaries, security levels. This environment is provided by application servers such as Jboss,Weblogic,Websphere.
2. Non-managed Environment: The basic configuration template is provided by this interface. Tomcat is one of the examples that best supports this environment.
Answer :2
Programmatic configuration
The org.hibernate.cfg.Configuration instance can be instantiated directly by specifying XML mapping documents. If the mapping files are in the classpath, use addResource().
Configuration cfg = new Configuration()
.addResource(“Item.hbm.xml”)
.addResource(“Bid.hbm.xml”);
An alternative way is to specify the mapped class and allow Hibernate to find the mapping document:
Configuration cfg = new Configuration()
.addClass(org.hibernate.auction.Item.class)
.addClass(org.hibernate.auction.Bid.class);
org.hibernate.cfg.Configuration also allows you to specify configuration properties:
Configuration cfg = new Configuration()
.addClass(org.hibernate.auction.Item.class)
.addClass(org.hibernate.auction.Bid.class)
.setProperty(“hibernate.dialect”, “org.hibernate.dialect.MySQLInnoDBDialect”)
.setProperty(“hibernate.connection.datasource”, “java:comp/env/jdbc/test”)
.setProperty(“hibernate.order_updates”, “true”);
Alternative options include:
Passing an instance of java.util.Properties to Configuration.setProperties().
Placing a file named hibernate.properties in a root directory of the classpath.
Setting System properties using java -Dproperty=value.
Including <property> elements in hibernate.cfg.xml (this is discussed later).
Hibernate JDBC Properties:
hibernate.connection.driver_class
hibernate.connection.url
hibernate.connection.username
hibernate.connection.password
hibernate.connection.pool_size
What is a Session? Can you share a session object between different threads?
Session is a light weight and a non-threadsafe object (No, you cannot share it between threads) that represents a single unit-of-work with the database. Sessions are opened by a SessionFactory and then are closed when all work is complete. Session is the primary interface for the persistence service. A session obtains a database connection lazily (i.e. only when required). To avoid creating too many sessions ThreadLocal class can be used as shown below to get the current session no matter how many times you make call to the currentSession() method.
public class HibernateUtil {
public static final ThreadLocal local = new ThreadLocal();
public static Session currentSession() throws HibernateException
{
Session session = (Session) local.get();
//open a new session if this thread has no session
if(session == null)
{
session = sessionFactory.openSession();
local.set(session);
}
return session;
}
}
It is also vital that you close your session after your unit of work completes. Note: Keep your Hibernate Session API handy.
Explain the role of Session interface in Hibernate?
In hibernate, the Session interface wraps a JDBC connection, holds a mandatory (first-level) cache of persistent objects, used when navigating the object graph or looking up objects by identifier and is a factory for Transaction
• Session session = sessionFactory.openSession();
• The Session interface is the primary interface used by Hibernate applications.
• It is a single-threaded, short-lived object representing a conversation between the application and the persistent store.
• It allows you to create query objects to retrieve persistent objects.
What is a SessionFactory? Is it a thread-safe object?
SessionFactory is Hibernates concept of a single datastore and is threadsafe so that many threads can access it concurrently and request for sessions and immutable cache of compiled mappings for a single database. A SessionFactory is usually only built once at startup. SessionFactory should be wrapped in some kind of singleton so that it can be easily accessed in an application code.
SessionFactory sessionFactory = new Configuration().configure().buildSessionfactory();
State the role of SessionFactory interface plays in Hibernate?
An application obtains Session instances from a SessionFactory which is typically single for the whole application created during its initialization.
• The SessionFactory caches generate SQL statements and other mapping metadata that Hibernate uses at runtime.
• It also holds cached data that has been read in one unit of work and may be reused in a future unit of work.
SessionFactory sessionFactory = configuration.buildSessionFactory();
What should SessionFactory be placed so that it can be easily accessed?
As far as it is compared to J2EE environment, if the SessionFactory is placed in JNDI then it can be easily accessed and shared between different threads and various components that are hibernate aware. You can set the SessionFactory to a JNDI by configuring a property hibernate.session_factory_name in the hibernate.properties file.
What does hibernate.properties file consist of?
This is a property file that should be placed in application class path. So when the Configuration object is created, hibernate is first initialized. At this moment the application will automatically detect and read this hibernate.properties file.
hibernate.connection.datasource = java:/comp/env/jdbc/AuctionDB
hibernate.transaction.factory_class = net.sf.hibernate.transaction.JTATransactionFactory
hibernate.transaction.manager_lookup_class = net.sf.hibernate.transaction.JBossTransactionManagerLookup
hibernate.dialect = net.sf.hibernate.dialect.PostgreSQLDialect
What is meant by Method chaining?
Method chaining is a programming technique that is supported by many hibernate interfaces. This is less readable when compared to actual java code. And it is not mandatory to use this format. Look how a SessionFactory is created when we use method chaining.
SessionFactory sessions = new Configuration()
.addResource(“myinstance/MyConfig.hbm.xml”)
.setProperties( System.getProperties() )
.buildSessionFactory();
What do you create a SessionFactory?
Configuration cfg = new Configuration();
cfg.addResource(“myinstance/MyConfig.hbm.xml”);
cfg.setProperties( System.getProperties() );
SessionFactory sessions = cfg.buildSessionFactory();
First, we need to create an instance of Configuration and use that instance to refer to the location of the configuration file. After configuring this instance is used to create the SessionFactory by calling the method buildSessionFactory().
What is the file extension you use for hibernate mapping file?
The name of the file should be like this : filename.hbm.xml The filename varies here. The extension of these files should be “.hbm.xml”. This is just a convention and it’s not mandatory. But this is the best practice to follow this extension.
What are different environments to configure hibernate?
There are mainly two types of environments in which the configuration of hibernate application differs.
i. Managed environment – In this kind of environment everything from database connections, transaction boundaries, security levels and all are defined. An example of this kind of environment is environment provided by application servers such as JBoss, Weblogic and WebSphere.
ii. Non-managed environment – This kind of environment provides a basic configuration template. Tomcat is one of the best examples that provide this kind of environment.
What is a hibernate xml mapping document and how does it look like?
In order to make most of the things work in hibernate, usually the information is provided in an xml document. This document is called as xml mapping document. The document defines, among other things, how properties of the user defined persistence classes’ map to the columns of the relative tables in database.
<?xml version=”1.0″?> <!DOCTYPE hibernate-mapping PUBLIC
“http://hibernate.sourceforge.net/hibernate-mapping-2.0.dtd”>
<hibernate-mapping>
<class name=”sample.MyPersistanceClass” table=”MyPersitaceTable”>
<id name=”id” column=”MyPerId”> <generator class=”increment”/>
</id>
<property name=”text” column=”Persistance_message”/>
<many-to-one name=”nxtPer” cascade=”all” column=”NxtPerId”/>
</class>
</hibernate-mapping>
Everything should be included under tag. This is the main tag for an xml mapping document.
How does hibernate code looks like?
Session session = getSessionFactory().openSession();
Transaction tx = session.beginTransaction();
MyPersistanceClass mpc = new MyPersistanceClass (“Sample App”);
session.save(mpc);
tx.commit();
session.close();
The Session and Transaction are the interfaces provided by hibernate.
What are Callback interfaces?
These interfaces are used in the application to receive a notification when some object events occur. Like when an object is loaded, saved or deleted. There is no need to implement callbacks in hibernate applications, but they’re useful for implementing certain kinds of generic functionality.
What are Extension interfaces?
When the built-in functionalities provided by hibernate is not sufficient enough, it provides a way so that user can include other interfaces and implement those interfaces for user desire functionality. These interfaces are called as Extension interfaces.
What are the Extension interfaces that are there in hibernate?
There are many extension interfaces provided by hibernate.
ProxyFactory interface - used to create proxies
ConnectionProvider interface – used for JDBC connection management
TransactionFactory interface – Used for transaction management
Transaction interface – Used for transaction management
TransactionManagementLookup interface – Used in transaction management.
Cahce interface – provides caching techniques and strategies
CacheProvider interface – same as Cache interface
ClassPersister interface – provides ORM strategies
IdentifierGenerator interface – used for primary key generation
Dialect abstract class – provides SQL support.
What the Core interfaces are of hibernate framework?
The core interfaces of hibernate framework are :
i. Session Interface – This is the primary interface used by hibernate applications. The instances of this interface are lightweight and are inexpensive to create and destroy. Hibernate sessions are not thread safe.
ii. SessionFactory Interface – This is a factory that delivers the session objects to hibernate application. Generally there will be a single SessionFactory for the whole application and it will be shared among all the application threads.
iii. Configuration Interface – This interface is used to configure and bootstrap hibernate. The instance of this interface is used by the application in order to specify the location of hibernate specific mapping documents.
iv. Transaction Interface – This is an optional interface but the above three interfaces are mandatory in each and every application. This interface abstracts the code from any kind of transaction implementations such as JDBC transaction, JTA transaction.
v. Query and Criteria Interface – This interface allows the user to perform queries and also control the flow of the query execution.
Explain the general flow of Hibernate communication with RDBMS?
What is difference between openSession() and getCurrentSession()?
Explain about Hibernate Object Life Cycle?
https://myjourneyonjava.blogspot.in/2014/12/explain-about-hibernate-object-life.html
What is the difference between session.get() method and session.load() method in Hibernate?
https://myjourneyonjava.blogspot.in/2013/12/different-between-sessionget-and.html
https://myjourneyonjava.blogspot.in/2014/12/explain-about-hibernate-object-life.html
What is the difference between session.get() method and session.load() method in Hibernate?
https://myjourneyonjava.blogspot.in/2013/12/different-between-sessionget-and.html
Explain the types of Hibernate instance states.
https://myjourneyonjava.blogspot.in/2014/12/explain-about-hibernate-object-life.html
How does Hibernate distinguish between transient (i.e. newly instantiated) and detached objects?
- Hibernate uses the version property, if there is one.
- If not uses the identifier value. No identifier value means a new object. This does work only for Hibernate managed surrogate keys. Does not work for natural keys and assigned (i.e. not managed by Hibernate) surrogate keys.
- Writting our own strategy with Interceptor.isUnsaved().
How would you reach detached objects to a session when the same object has already been loaded into the session?
We can use the session.merge() method.
What are the benefits of detached objects?
Detached objects can be passed across layers all the way up to the presentation layer without having to use any DTOs (Data Transfer Objects). You can later on re-attach the detached objects to another session.
Explain the advantages and disadvantages of detached objects?
Advantages:
- Detached objects passing can be done across layers upto the presentation layer without using Data Transfer Objects.
- At the time of using long transactions by the user which needs long think-time, it is suggested to split these transactions into some transactions. The detached objects get modified apart from the transaction scope which then can be re-attached to a new transaction.
Disadvantages:
- The usage of detached objects are cumbersome and cryptic. It is suggested not to be cluttered with the session, if possible.
- It is recommended to use DataTransferObjects and DomainObjects that is used to maintain separation between the user interfaces and the Service.
What is the difference between the session.update() method and the session.lock() method?
Both update() and merge() methods are intended for re-attaching a detached object. The session.lock() method simply reattaches the object to the session without checking or updating the database on the assumption that the database in sync with the detached object. It is the best practice to use either session.update(). Use session.lock() only if you are absolutely sure that the detached object is in sync with your detached object or if it does not matter because you will be overwriting all the columns that would have changed later on within the same transaction.
What is the difference between session.merge() and session.update()?
Both update() and merge() methods in hibernate are used to convert the object which is in detached state into persistence state.
update () : When the session does not contain an persistent instance with the same identifier, and if it is sure use update for the data persistence in hibernate.
merge (): Irrespective of the state of a session, if there is a need to save the modifications at any given time, use merge().
What are Collection types in Hibernate?
There are five collection types in hibernate:
- Bag
- Set
- List
- Array
- Map
What is the difference between sorted collection and ordered collection in hibernate?
Sorted Collection:
The sorted collection is a collection that is sorted using the Java collections framework. The sorting is done in the memory of JVM that is running hibernate, soon after reading the data from the database using Java Comparator. The entity bean should implement Comparable and Comparator.
The less the collection the more the efficient of sorting.
Ordered Collection:
The ordered collection will also sorts a collection by using the order by clause for the results fetched.
The more the collection, the more efficient of sorting.
List<Employee> empList = session.createCriteria(Employee.class)
.addOrder(Order.desc("id")).list();
How to implement Joins in Hibernate?
There are various ways to implement joins in hibernate.
How transaction management works in Hibernate?
Transaction management is very easy in hibernate because most of the operations are not permitted outside of a transaction. So after getting the session from SessionFactory, we can call session beginTransaction() to start the transaction. This method returns the Transaction reference that we can use later on to either commit or rollback the transaction.
Overall hibernate transaction management is better than JDBC transaction management because we don’t need to rely on exceptions for rollback. Any exception thrown by session methods automatically rollback the transaction.
What are the different design patterns are used in Hibernate framework?
Some of the design patterns are used in Hibernate Framework:
What is Hibernate Validator Framework?
Data validation is integral part of any application. We will find data validation at presentation layer with the use of Javascript, then at the server side code before processing it. Also data validation occurs before persisting it, to make sure it follows the correct format.
Validation is a cross cutting task, so we should try to keep it apart from our business logic. That’s why JSR303 and JSR349 provides specification for validating a bean by using annotations. Hibernate Validator provides the reference implementation of both these bean validation specs.
There are various ways to implement joins in hibernate.
- Using associations such as one-to-one, one-to-many etc.
- Using JOIN in the HQL query. There is another form “join fetch” to load associated data simultaneously, no lazy loading.
- We can fire native sql query and use join keyword.
How transaction management works in Hibernate?
Transaction management is very easy in hibernate because most of the operations are not permitted outside of a transaction. So after getting the session from SessionFactory, we can call session beginTransaction() to start the transaction. This method returns the Transaction reference that we can use later on to either commit or rollback the transaction.
Overall hibernate transaction management is better than JDBC transaction management because we don’t need to rely on exceptions for rollback. Any exception thrown by session methods automatically rollback the transaction.
How to use application server JNDI DataSource with Hibernate framework?
For web applications, it’s always best to allow servlet container to manage the connection pool. That’s why we define JNDI resource for DataSource and we can use it in the web application. It’s very easy to use in Hibernate, all we need is to remove all the database specific properties and use below property to provide the JNDI DataSource name.
<property name="hibernate.connection.datasource">java:comp/env/jdbc/MyDB</property>
Some of the design patterns are used in Hibernate Framework:
- Factory pattern in SessionFactory.
- Proxy Pattern for lazy loading.
- Domain Model Pattern – An object model of the domain that incorporates both behavior and data.
- Data Mapper – A layer of Mappers that moves data between objects and a database while keeping them independent of each other and the mapper itself.
What is Hibernate Validator Framework?
Data validation is integral part of any application. We will find data validation at presentation layer with the use of Javascript, then at the server side code before processing it. Also data validation occurs before persisting it, to make sure it follows the correct format.
Validation is a cross cutting task, so we should try to keep it apart from our business logic. That’s why JSR303 and JSR349 provides specification for validating a bean by using annotations. Hibernate Validator provides the reference implementation of both these bean validation specs.
What is the benefit of Hibernate Tools Eclipse plugin?
Hibernate Tools plugin helps us in writing hibernate configuration and mapping files easily. The major benefit is the content assist to help us with properties or xml tags to use. It also validates them against the Hibernate DTD files, so we know any mistakes before hand.
What is lazy fetching in hibernate?
• Lazy setting decides whether to load child objects while loading the Parent Object.
• This can be done by a setting in hibernate mapping file of the parent class.Lazy = true
• By default the lazy loading of the child objects is true.
What is lazy initialization in hibernate?
The delaying the object creation or calculating a value or some process until the first time it is needed. The retrieval of particular information only at the time when the object is accessed, is lazy initialization in hibernate. A scenario for lazy initialization is:
When the field creation is expensive, a field may or may not be invoked.
In this scenario the creation of a field can be deferred until the actual moment is arise to use it. The performance is increased using this technique, by avoiding unnecessary creation of objects which is expensive and consumes the memory space.
What is Hibernate proxy?
What is Hibernate proxy?
Mapping of classes can be made into a proxy instead of a table. A proxy is returned when actually a load is called on a session. The proxy contains actual method to load the data. The proxy is created by default by Hibernate, for mapping a class to a file. The code to invoke Jdbc is contained in this class.
What are managed associations and hibernate associations?
Associations that are related to container management persistence are called managed associations. These are bi-directional associations. Coming to hibernate associations, these are unidirectional.
What are the different approaches to represent an inheritance hierarchy?
What are the different approaches to represent an inheritance hierarchy?
There are three Inheritance Hierarchies
- Table per concrete class.
- Table per class hierarchy.
- Table per subclass.
• Typical and most common property mapping
<property name=”description” column=”DESCRIPTION” type=”string”/>
Or
<property name=”description” type=”string”>
<column name=”DESCRIPTION”/>
</property>
• Derived properties
<property name=”averageBidAmount” formula=”( select AVG(b.AMOUNT) from BID b
where b.ITEM_ID = ITEM_ID )” type=”big_decimal”/>
• Typical and most common property mapping
<property name=”description” column=”DESCRIPTION” type=”string”/>
• Controlling inserts and updates
<property name=”name” column=”NAME” type=”string”
insert=”false” update=”false”/>
Hibernate supports JPA annotations and it has some other annotations in org.hibernate.annotations package. Some of the important JPA and hibernate annotations used are:
- javax.persistence.Entity: Used with model classes to specify that they are entity beans.
- javax.persistence.Table: Used with entity beans to define the corresponding table name in database.
- javax.persistence.Id: Used to define the primary key in the entity bean.
- javax.persistence.EmbeddedId: Used to define composite primary key in the entity bean.
- javax.persistence.Column: Used to define the column name in database table.
- javax.persistence.GeneratedValue: Used to define the strategy to be used for generation of primary key. Used in conjunction with javax.persistence.GenerationType enum.
- javax.persistence.OneToOne: Used to define the one-to-one mapping between two entity beans. We have other similar annotations as OneToMany, ManyToOne and ManyToMany.
- org.hibernate.annotations.Cascade: Used to define the cascading between two entity beans, used with mappings. It works in conjunction with org.hibernate.annotations.CascadeType.
- javax.persistence.PrimaryKeyJoinColumn: Used to define the property for foreign key. Used with org.hibernate.annotations.GenericGenerator and org.hibernate.annotations.Parameter.
- javax.persistence.Access: Used to define the access type, either field or property. Default value is field and if you want hibernate to use getter/setter methods then you need to set it to property.
What is cascading in hibernate?
When we have relationship between entities, then we need to define how the different operations will affect the other entity. This is done by cascading and there are different types of it.
Here is a simple example of applying cascading between primary and secondary entities.
What are different types of cascading?
Commonly used cascading types as defined in CascadeType enum are:
When we have relationship between entities, then we need to define how the different operations will affect the other entity. This is done by cascading and there are different types of it.
Here is a simple example of applying cascading between primary and secondary entities.
import org.hibernate.annotations.Cascade; @Entity @Table(name = "EMPLOYEE") public class Employee { @OneToOne(mappedBy = "employee") @Cascade(value = org.hibernate.annotations.CascadeType.ALL) private Address address; }
Note that Hibernate CascadeType enum constants are little bit different from JPA javax.persistence.CascadeType, so we need to use the Hibernate CascadeType and Cascade annotations for mappings, as shown in above example.What are different types of cascading?
Commonly used cascading types as defined in CascadeType enum are:
- None: No Cascading, it’s not a type but when we don’t define any cascading then no operations in parent affects the child.
- ALL: Cascades save, delete, update, evict, lock, replicate, merge, persist. Basically everything
- SAVE_UPDATE: Cascades save and update, available only in hibernate.
- DELETE: Corresponds to the Hibernate native DELETE action, only in hibernate.
- DETATCH, MERGE, PERSIST, REFRESH and REMOVE – for similar operations
- LOCK: Corresponds to the Hibernate native LOCK action.
Explain the difference between Hibernate and Spring?
Hibernate is an ORM tool for data persistency. Spring is a framework for enterprise applications. Spring supports hibernate and provides the different classes which are templates that contains the common code.
What is a HibernateTemplate?
HibernateTemplate is a helper class that is used to simplify the data access code. This class supports automatically converts HibernateExceptions which is a checked exception into DataAccessExceptions which is an unchecked exception. HibernateTemplate is typically used to implement data access or business logic services. The central method is execute(), that supports the Hibernate code that implements HibernateCallback interface.
What are the benefits of HibernateTemplate?
The benefits of HibernateTemplate are:
- HibernateTemplate, which is a Spring Template class, can simplify the interactions with Hibernate Sessions.
- Various common functions are simplified into single method invocations.
- The sessions of hibernate are closed automatically
- The exceptions will be caught automatically, and converts them into runtime exceptions.
How to integrate Hibernate and Spring frameworks?
Following steps are required to integrate Spring and Hibernate frameworks together.
Following steps are required to integrate Spring and Hibernate frameworks together.
- Add hibernate-entitymanager, hibernate-core and spring-orm dependencies.
- Create Model classes and corresponding DAO implementations for database operations. Note that DAO classes will use SessionFactory that will be injected by Spring Bean configuration.
- If you are using Hibernate 3, you need to configure org.springframework.orm.hibernate3.LocalSessionFactoryBean or org.springframework.orm.hibernate3.annotation.AnnotationSessionFactoryBean in Spring Bean configuration file. For Hibernate 4, there is single class org.springframework.orm.hibernate4.LocalSessionFactoryBean that should be configured.
- Note that we don’t need to use Hibernate Transaction Management, we can leave it to Spring declarative transaction management using @Transactional annotation.
What is Hibernate Query Language (HQL)?
Hibernate Query Language is designed for data management using Hibernate technology. It is completely object oriented and hence has notions like inheritance, polymorphism and abstraction. The queries are case-sensitive. This has an exception for Java classes and properties. The query operations are through objects. HQL acts as a bridge between Objects and RDBMS.
What are the differences ways to get the JDBC connection in Hibernate?
https://myjourneyonjava.blogspot.in/2014/12/different-ways-to-get-connection-object.html
What are the differences ways to get the JDBC connection in Hibernate?
https://myjourneyonjava.blogspot.in/2014/12/different-ways-to-get-connection-object.html
In hibernate while closing session using close() method does it automatically flush() the session.
Hibernate doesn't call session.flush() method automatically while closing the session using session.close(). See the code.
What are best practices to follow with Hibernate framework?
Some of the best practices to follow in Hibernate are:
- Always check the primary key field access, if it’s generated at the database layer then you should not have a setter for this.
- By default hibernate set the field values directly, without using setters. So if you want hibernate to use setters, then make sure proper access is defined as @Access(value=AccessType.PROPERTY).
- If access type is property, make sure annotations are used with getter methods and not setter methods. Avoid mixing of using annotations on both filed and getter methods.
- Use native sql query only when it can’t be done using HQL, such as using database specific feature.
- If you have to sort the collection, use ordered list rather than sorting it using Collection API.
- Use named queries wisely, keep it at a single place for easy debugging. Use them for commonly used queries only. For entity specific query, you can keep them in the entity bean itself.
- For web applications, always try to use JNDI DataSource rather than configuring to create connection in hibernate.
- Avoid Many-to-Many relationships, it can be easily implemented using bidirectional One-to-Many and Many-to-One relationships.
- For collections, try to use Lists, maps and sets. Avoid array because you don’t get benefit of lazy loading.
- Do not treat exceptions as recoverable, roll back the Transaction and close the Session. If you do not do this, Hibernate cannot guarantee that in-memory state accurately represents the persistent state.
- Prefer DAO pattern for exposing the different methods that can be used with entity bean
- Prefer lazy fetching for associations.
There are two ways to enable SQL logging.
1. Enable the SQL statements logging in the Hibernate using configuration properties by setting the hibernate.show_sql property to true:
Programmatic Configuration:
Configuration configuration = new Configuration(); configuration.setProperty("hibernate.show_sql", "true"); // setting the additional parameters SessionFactory sf = configuration.buildSessionFactory();
XML configuration:<property name="hibernate.show_sql">true</property>
In this one, SQL statements are always logged to System.out when the property is enabled and on some servers System.out is not accessible.Note: We shouldn't enable this one in production environment.
2. Using log4j framework:
What are the general considerations or best practices for defining your Hibernate persistent classes?log4j.logger.org.hibernate.SQL=TRACE, SQL_APPENDER log4j.additivity.org.hibernate.SQL=false
1.We must have a default no-argument constructor for our persistent classes and there should be getXXX() (i.e accessor/getter) and setXXX() i.e. mutator/setter) methods for all our persistable instance variables.
2.We should implement the equals() and hashCode() methods based on our business key and it is important not to use the id field in your equals() and hashCode() definition if the id field is a surrogate key (i.e. Hibernate managed identifier). This is because the Hibernate only generates and sets the field when saving the object.
3. It is recommended to implement the Serializable interface. This is potentially useful if you want to migrate around a multi-processor cluster.
4.The persistent class should not be final because if it is final then lazy loading cannot be used by creating proxy objects.
5.Use XDoclet tags for generating your *.hbm.xml files or Annotations (JDK 1.5 onwards), which are less verbose than *.hbm.xml files.






11 comments:
Nice
Good Post! Thank you so much for sharing this pretty post, it was so good to read and useful to improve my knowledge as updated one, keep blogging.
Hibernate Training in Electronic City
I really liked your blog post.Much thanks again. Awesome.
SAP Secrity online training
oracle sql plsql online training
go langaunage online training
azure online training
java online training
salesforce online training
hadoop online training
mulesoft online training
linux online training
etl testing online training
I really enjoy the blog article.Much thanks again.
salesforce training
salesforce online training
Hibernate Interview Questions and Answers
Good Post!!!! Thanks for it...
Selenium Automated Testing
What is Selenium
Perfect post with amazing information and thanks for sharing!!
Digital Marketing Course in Pune
Digital Marketing Course in Hyderabad
Great work with lots of knowledgeable information and thanks for sharing!!
DATA Science Course in Hyderabad
DATA Science Course in Mumbai
Perfect post with amazing information and thanks for sharing!!
DevOps Training in Ahmedabad
DevOps Training in Trivandrum
Perfect post with amazing information and thanks for sharing!!
AWS Training in Gurgaon
AWS Training in Ahmedabad
AWS Training in Kolkata
Post a Comment